「この議事録の要約を作って」「このプログラムコードのバグを見つけて」「このクライアントへの謝罪メールを書いて」
今や私たちの業務に欠かせない「優秀なアシスタント」となったChatGPTなどの生成AI。業務効率化のために日常的に利用している方も多いでしょう。しかし、その便利な入力欄に、「入力してはいけない情報」を無意識に打ち込んでいませんか?
もし、あなたが入力したその「社外秘の売上データ」や「未発表の新製品情報」が、AIの学習に使われ、競合他社の社員がChatGPTを使ったときに「回答」として表示されてしまったらどうなるでしょうか?
この記事では、生成AIの利用が急速に広まる今だからこそ知っておくべき、「AIへのデータ入力リスク(情報漏洩)」の仕組みから、世界で実際に起きた事故、そして「正しく怖がり、賢く使う」ための具体的な設定方法とガイドラインまでを徹底解説します。
Contents
1. なぜ「入力」が危険なのか? 生成AIの学習メカニズム
まず、なぜChatGPTなどに情報を入力することがリスクになるのか、その根本的な仕組みを理解しましょう。
あなたの入力データは「先生」の教材になる
多くの生成AIサービス(特に無料版や、初期設定のままのコンシューマー向けプラン)では、ユーザーとのチャット履歴を、将来のモデルのトレーニング(学習)データとして利用する規約になっています。
これは、AIがより賢く、より自然な対話ができるようにするための仕組みですが、セキュリティの観点からは大きなリスクを孕んでいます。あなたが入力した情報は、巨大なデータベースの一部として取り込まれ、AIという「脳」の中に知識として蓄積される可能性があるのです。
OpenAI社のプライバシーポリシー(参考)
OpenAIは、サービス向上のために、ユーザーのコンテンツ(プロンプトやアップロードファイルなど)をモデルのトレーニングに使用する場合があります。
※ただし、API経由やEnterprise版ではデフォルトで学習利用されない仕様になっています(後述)。
「公開広場で内緒話をする」のと同じ
イメージしてください。あなたが会社の会議室(ローカル環境)で話しているつもりでも、ChatGPTの入力欄に打ち込むという行為は、インターネット上の「巨大な公開広場」で、拡声器を使ってその内容を話しているのに近い状態になり得るのです。
一度学習されてしまったデータを取り消すことは、技術的に非常に困難です。AIは「事実」としてそれを記憶するのではなく、確率的な結びつきとして取り込むため、「あのデータだけ削除して」という外科手術のような削除が難しいのです。
2. 実際に起きた「AI情報漏洩」インシデント事例
「そんな偶然、滅多に起きないだろう」と思いますか? しかし、生成AIのブームが始まった直後から、実際に企業での情報漏洩事故は発生しています。

【事例1】Samsung(サムスン)の機密コード流出事件
最も有名で、世界中の企業に衝撃を与えたのが、2023年初頭に報じられたSamsungの事例です。
- 発生状況:Samsungの半導体部門のエンジニアが、業務効率化のためにChatGPTを利用していました。
- 何をしたか:
- バグのある機密ソースコードをそのままChatGPTに貼り付け、「修正して」と依頼した。
- 会議の録音データを文字起こしし、その内容をChatGPTに入力して「議事録の要約」を作成させた。
- 結果:これらはSamsung独自の半導体技術に関する極秘情報でしたが、外部サーバー(OpenAI)に送信されてしまいました。
- その後:Samsungはこの事態を受けて、一時的に社内での生成AI利用を全面的に禁止しました。
出典:Bloomberg: Samsung Bans ChatGPT Use by Staff After Leak (2023)
【統計データ】企業データの4.9%がAIにペーストされている
データセキュリティ企業のCyberhavenが2023年に発表したレポートによると、AI利用におけるリスクの実態が浮き彫りになっています。
| 調査項目 | 結果データ |
|---|---|
| AIを利用した従業員割合 | 全従業員の約11%が職場でChatGPTを利用 |
| 機密データを貼り付けた割合 | 利用者のうち、会社の機密データをChatGPTに入力していたのは4.9% |
| 入力された情報の種類 | 顧客データ、ソースコード、規制対象データ、患者の医療情報など |
出典:Cyberhaven “The risks of using ChatGPT at work” (2023)
このデータは2023年時点のものです。AIの普及が進んだ現在、対策を講じていない企業では、さらに多くの情報が「コピペ」されている可能性があります。
3. もう一つの脅威:ディープフェイクと「AIソーシャル・エンジニアリング」
情報の「入力(漏洩)」だけでなく、AIによって生成されたコンテンツによる「騙し」も、最新のセキュリティリスクです。特に「ディープフェイク(AIによる偽動画・偽音声)」の技術は、もはや人間の目や耳では見抜けないレベルに達しています。
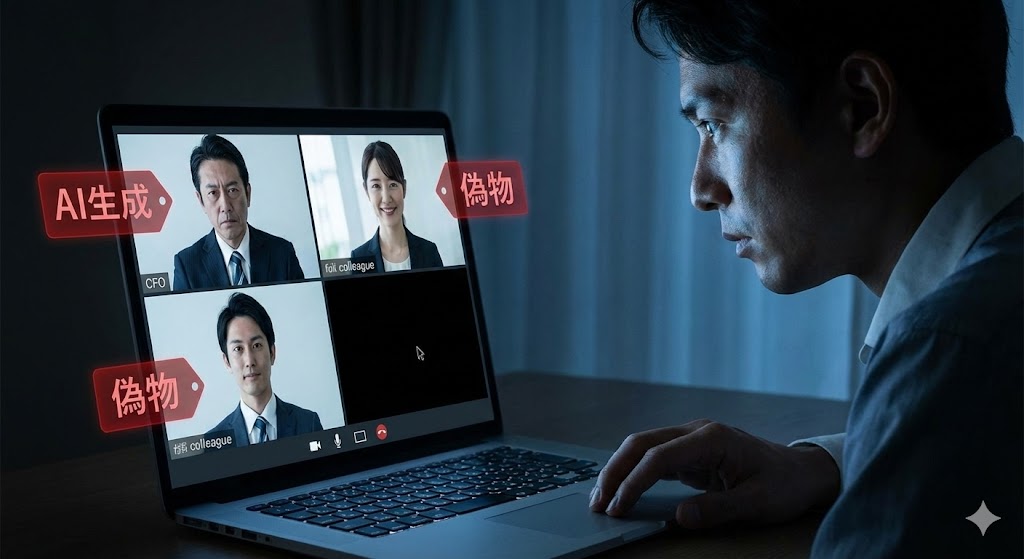
【事例2】香港の巨額詐欺事件:Web会議の参加者が「全員AI」
2024年2月、香港で発生した事件は、世界中のセキュリティ担当者を震撼させました。
- 事件概要:多国籍企業の香港支社の財務担当者が、2億香港ドル(約38億円)を騙し取られました。
- 手口:
- まず、英国本社のCFO(最高財務責任者)を名乗る人物から「機密取引を行う必要がある」とメールが届きました。
- 担当者は当初詐欺を疑いましたが、その後招待された「ビデオ会議」に参加して信用してしまいました。
- なぜなら、そのWeb会議にはCFOだけでなく、見知った同僚や他の役員なども参加しており、全員が本物そっくりの顔と声で話していたからです。
- 真相:会議に参加していた「自分以外の全員」が、AIによってリアルタイム生成されたディープフェイクでした。過去の動画や音声データから学習して作られた「デジタル・クローン」だったのです。
出典:CNN.co.jp: フェイク動画の会議で38億円詐取、社員以外「全員偽物」 香港 (2024.02.05)
これは、「顔を見て話せば本人確認になる」というこれまでの常識が、AI時代には通用しなくなったことを示しています。
4. 今すぐできる対策:AIを「学習させない」設定と使い分け
恐怖ばかり煽りましたが、生成AIは正しく設定し、正しく使えば、これほど強力な武器はありません。ここでは具体的な「防衛策」を解説します。
【個人・現場レベル】ChatGPTの「オプトアウト」設定
無料版やPlus版(個人有料版)のChatGPTを使っていて、まだ設定を変更していない方は、今すぐ以下の設定を確認してください。これにより、自分の入力データがAIの学習に使われるのを拒否(オプトアウト)できます。
設定手順(Webブラウザ版の場合)
- 画面左下のユーザー名またはアイコンをクリック
- 「Settings(設定)」を選択
- 「Data controls(データコントロール)」を選択
- 「Improve the model for everyone(モデルの改善)」という項目(またはそれに類するスイッチ)を「OFF」にする
※以前は「Chat History & Training」という名称でしたが、UIの更新により履歴保存と学習設定が分離されました(一時的なチャット機能など)。最新のUIを確認し、「モデルの改善にデータを使用しない」設定を探してください。
【企業・組織レベル】安全な環境の導入
業務で本格的にAIを活用する場合、個人の無料アカウントを使わせることは推奨できません。「Shadow AI(会社が把握していないAI利用)」の温床になるからです。以下のいずれかの導入を検討すべきです。
| サービス形態 | データ学習の扱い | セキュリティ推奨度 |
|---|---|---|
| ChatGPT (無料版/Plus) | デフォルトで学習される
(設定でOFF可能だが個人任せになる) |
低(業務利用は非推奨) |
| ChatGPT Team / Enterprise | デフォルトで学習されない
企業管理下のワークスペース |
高 |
| API利用
(OpenAI API / Azure OpenAI) |
デフォルトで学習されない
自社システムへの組み込み用 |
最高(自社ポリシーを適用可能) |
特にマイクロソフトが提供する「Azure OpenAI Service」などは、入力データがOpenAI社の学習に使われず、企業のコンプライアンス要件を満たしやすい設計になっています。
5. 生成AI利用ガイドラインの策定:「信号機ルール」のススメ
ツールを導入しても、運用ルールがなければ事故は起きます。しかし、「全面禁止」にすると社員は隠れて使い始めます。そこで推奨されるのが、データの機密レベルに応じた「信号機ルール」です。
🚦 生成AIデータ入力の信号機ルール(例)
【赤信号】絶対に入力してはいけない情報
- 個人情報(PII): 顧客の氏名、住所、電話番号、マイナンバー、クレジットカード情報など
- 機密性の高い社外秘情報: 未発表の新製品スペック、M&A情報、未公開の決算データ、システムのパスワードやAPIキー
- 他社の権利物: 著作権で保護されている第三者の文章やコードを無断で解析させること
【黄信号】加工すれば入力してもよい情報(匿名化・マスキング)
- 社内会議の議事録: 固有名詞(A社、B部長など)を「X社」「担当者」などに置換したもの
- プログラムコード: 固有のIPアドレスや認証情報を含まない、汎用的なロジック部分のみ
- メールの下書き: 相手の社名や具体的な取引額を伏せた状態のテンプレート作成
【青信号】入力しても問題ない情報
- 公開情報(Public): すでにWebサイトで公開されているプレスリリース、カタログ情報
- 一般的な知識: 歴史的な事実、エクセルの関数の書き方、一般的なビジネスメールの挨拶文
- アイデア出し: 特定の事実に基づかない、ブレインストーミングやキャッチコピーの案出し
「マスキング」のテクニックを覚えよう
業務で使う場合、最も重要なスキルは「プロンプトエンジニアリング」よりも「マスキング(匿名化)」です。
- × 「株式会社田中の鈴木社長への謝罪メールを書いて」
- ○ 「取引先の社長への謝罪メールを書いて。相手は長年の付き合いがある製造業の企業。」
このように、具体的な固有名詞を抽象化するだけで、情報漏洩のリスクはほぼゼロに近づきます。AIは文脈さえ分かれば、固有名詞がなくても適切な文章を作成できます。
まとめ:AIは「口の軽い優秀な新人」だと思って付き合う
生成AIは、人類が手にした素晴らしいツールです。しかし、セキュリティの観点から見れば、それは「仕事はめちゃくちゃ早くて優秀だけど、酔っ払うと居酒屋で会社の秘密を大声で喋ってしまう新人」のような存在だと考えてください。
そんな新人に重要な仕事を任せるとき、あなたならどうしますか?
- 「ここだけの話だけど…」といった秘密は教えない。
- 重要な数字や固有名詞は伏せて指示を出す。
- 彼が作った成果物(回答)が正しいかどうか、必ず上司(あなた)がチェックする。
この姿勢こそが、生成AI時代の新しいセキュリティ・マナーです。
技術的な「オプトアウト設定」を行うことはもちろんですが、最終的に会社を守るのは、キーボードを叩く私たち一人ひとりの「これは入力して大丈夫かな?」という一瞬の躊躇(ためらい)と確認です。
さあ、この記事を読んだ後すぐに、ご自身のChatGPTの設定画面を確認してみてください。それが、あなたとあなたの会社を守る第一歩になります。


